Posted: Sept. 11, 2014, 8:27 a.m. by Rachel Stone
As the useful links page of the website makes clear, researchers have developed a number of different medieval charter databases. The design of such databases varies, depending on the aim of the project and the technologies available. This series of blog posts aims to explain in more detail than would be possible in an article or conference paper, both how the Making of Charlemagne's Europe project database was structured and why we made the decisions we did. The main emphasis is on how our data structures relate to the specific characteristics of the content they hold (early medieval charters). While the technology continues to advance, many basic problems will remain in deciding how to represent the information in medieval documents in a standard format.
RELATIONAL DATABASE OR MARK-UP?
The first decision was made when the database was conceived of: that the aim would be to create a relational database with information extracted from charters rather than using a mark-up language such as TEI to tag the full text of charters with additional information. There were a number of reasons for this decision, but one central factor was the type and scope of information in which we were interested. Mark-up of texts centres on documents as textual artefacts and makes most sense for a collection of texts that are relatively homogenous (such as the Fine Rolls project, with its corpus of offers of money to Henry III) or where the emphasis is on linguistic features (such as Langscape, which looks at estate boundaries).
In contrast, extraction of data is the more realistic option when the aim is to compare texts that have very little standardisation. As an example, the Fine Rolls project shows how a reference to "Phillip Marc, sheriff of Nottingham" could be marked up:

The 'key' attributes refer to an authority 'table' that contain detailed information on the person 'Phillip Marc' and on the location 'Nottinghamshire'. Such mark-up is substantially easier when working with an English translation (and thus standardised spelling) and with a bureaucratic tradition in the underlying document that aims to identify people consistently.
In contrast, one of the difficulties that we soon realised when looking at Carolingian charter texts is how often they give even such basic information in a less than explicit form. An examples is provided by two charters from Wissembourg Abbey, both from the first half of 808 and written by the same scribe. Number 19 in Glöckner's edition is addressed to "Venerabili in Christo Iustulfo episcopus uel abbate de monasterio Uuizenburg" (Justulf, venerable in Christ, bishop and abbot of the monastery of Wissembourg) and talks of a donation "ad partem sancti Petri ad monasterium ipsius" (to the party of St Peter, to the monastery of him himself), and to the "casa sancti Petri Uuizenburg" (house of St Peter at Wissembourg). Number 20, in contrast, refers to "sacrosancto monasterio cuius uocabulum est Uuizeburg quod est constructum in pago Spirense super fluuio Lutra in honore sanctorum apostolorum Petri et Pauli, ubi uir uenerabilis Iustolfus episcopus preesse uidetur" (the holy monastery which is called Wissembourg, which is built in the county of Speyer on the river Lauter in honour of the apostles Peter and Paul, where the venerable man bishop Justulf is seen to preside). The donor gives "ad partem sancti Petri ipsius monasterium" (to the party of the monastery of St Peter himself) and refers later to "ipsa casa Dei" (the same house of God).
Justulf, the abbot at the time, thus appears in several different spelling/declensions, but references to him could be marked up with a link to a standardised name in a separate database (as with Phillip Marc in the Fine Rolls). Such a database could also include an important fact about Justulf that is never explicitly stated: that he is male. Mark-up language, however, would struggle to record Justulf as abbot of Wissembourg. He's explicitly said to be that in the first charter, but the second charter uses an equivalent phrase in which the term "abbas" never appears. Wissembourg, meanwhile, is given one patron saint in one charter and two in the other. And what sections of the text should be marked up as its "name"?
The conceptual framework of mark-up languages is not really suitable for systematic analysis of data from very loosely-structured texts such as these. Someone interested in small-scale diplomatics might find the variance in linguistic practice by a single scribe fascinating. For our project, working on large-scale comparisons of social phenomena and with thousands of charters to add, linguistic variability and circumlocutions such as these make extraction rather than mark-up the simpler option.
THE FACTOID MODEL
The method of data extraction that we decided to use is fundamentally underpinned by the "factoid" model of extracting information. This model was developed by previous KCL project teams when producing prosopographical databases, using relational database technology. At its most basic a factoid is an assertion made by the project team that a source ‘S’ at location ‘L’ states something (‘F’) about person ‘P’ (1). Such a model can be applied to any source from a saint's life to a coin (which explicitly or implicitly states that "X is a minter" or "Charlemagne is king of the Franks").
A factoid model can therefore be conceptualised as linking together different sorts of entities, as shown by a simplified data structure diagram for the People of Medieval Scotland database (2):
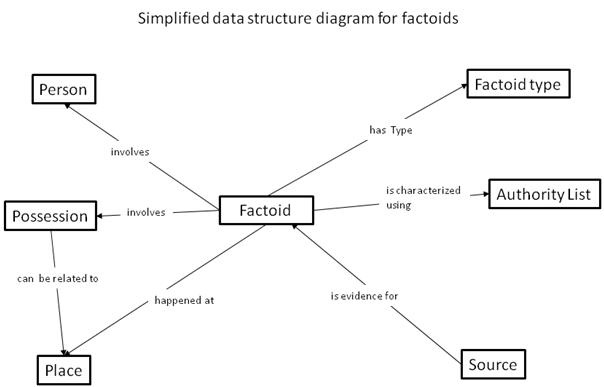
Factoids here are statements about persons, possessions and places derived from a source. These factoids are of varying types, depending on the content that they need to contain: for example, the data structures required for inputting the statement "Justulf is abbot of Wissembourg" are different from those for inputting the statement "Justulf petitioned Charlemagne to grant an immunity to the monastery of Wissembourg". Authority lists for such matters as types of transactions (sale, grant, exchange) or offices held (abbot, bailiff, bishop) are used to ensure that data is entered consistently, e.g. that Justulf is not described as "abbot" in one factoid and "abbas" in another.
Our project adapted this underlying factoid model with a couple of minor modifications. First of all, we were not interested only in individual persons, but also in corporate bodies (such as monasteries). The "person" entity was therefore renamed as Agent to reflect this. Secondly, we were using one basic source unit (a single charter). Our model was therefore of the form:
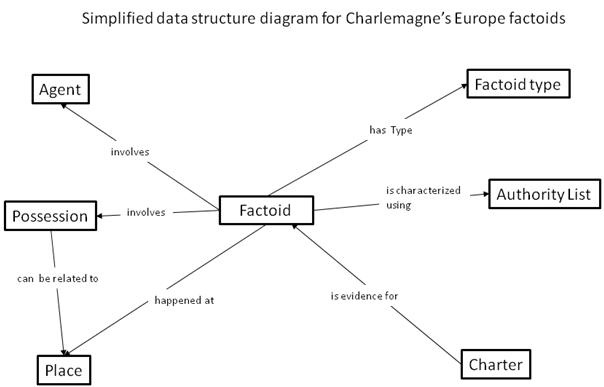
Within this overall structure, we created four different types of factoid:
1) Attribute/Relationship factoids, which record a characteristic of a particular agent or a relationship between two agents: "Justulf is abbot of Wissembourg", "Louis is the son of Charlemagne".
2) Place relationship factoids, which record medieval hierarchies of places: "Wissembourg is in the county of Speyer".
3) Transaction factoids, which record the specific business transacted in a charter, and which link together agents, possessions and places: "Reccho gives ten iurnales of land at Alteckendorf to Wissembourg".
4) Miscellaneous factoids, which record information given about events other than transactions: "Charlemagne conquered Italy".
THE CONCEPTUAL CHALLENGES OF CAROLINGIAN CHARTERS
The model outlined above is conceptually clear; unfortunately, however, Carolingian charters repeatedly blur the clear lines that ideally exist between entity types. There are four main ways in which they do this.
A) Charter as source versus charter as factoid
Charters are our source material, but the creation of a charter is also an event in itself: the majority of charters include details of when and by whom the particular document was written and witnessed. In theory, we should therefore have separated out conceptually an individual charter as a source from the events involved in the production of that charter (as the POMS database attempts to do: see this grant by King Malcolm to Kelso). In practice, the information for the two was combined, to avoid having to create two separate records for each charter.
B) People as possessions
Relatively few transactions in POMS deal with people being transferred as gifts: a few dozen out of more than 8000 records. In contrast, Carolingian Francia had a large population of unfree and other dependents and they are frequently mentioned in transactions. To be a slave is almost by definition to be a person who is also simultaneously a possession: we had to decide how to deal with such persons in the database.
At one level, it was akin to a moral decision: people who were being transacted should still be regarded as agents in the normal way, not put in some separate category of their own. But it was also a pragmatic decision. The charters tell us many of the same types of things about unfree people (and people being transacted who may or may not be unfree) as about other people: their names, their relatives, their occupations, where they live. We're sometimes even told about the unfree that they themselves possess. It makes sense to record details of them in the same structures that we use for any other agents, even if that does make for somewhat increased conceptual messiness within the database on what counts as a possession.
C) Places as possessions
Another issue we discovered as we began to experiment with inputting data is that it wasn't just people that could be transacted in charters but also places. Many charters included references to someone as donating "my property in villa X", but the database covers transactions made by everyone from peasant owners up to Charlemagne himself. Some large-scale donors gave entire villas to their favoured church or monastery.
The question is complicated by the variable meanings of "villa", which can mean estate or village among other things and whose exact meaning in any particular charter is often impossible to deduce. Nevertheless, it was clear that we needed to make some kind of distinction between a transaction involving property located "at" a particular place X and one involving property that consisted of the whole of place X. Our solution, therefore, was to regard places as potential possessions as well agents. Looking back, I'm not sure whether there's a better solution, which deals more effectively with this distinction between possessions in a place and the place itself. But it is one of the issues that anyone who's planning to include details of possessions in a database needs to consider carefully.
D) Churches as agents, possessions and places
One of the biggest headaches we had in conceptualising our data was how we dealt with churches. An early decision was that we didn't count the saints associated with them as agents. Even if someone says they're giving a gift to St Peter, it's actually going to Wissembourg (or Cluny or whichever other church it may be). This fitted with our focus on standardised data extracted from charters rather than the rhetoric of the charters themselves.
It was therefore easy to decide that monasteries were to be regarded as agents, who could receive donations, arrange exchanges, get involved in disputes and the like. The more complicated question was how to deal with churches and it's here that the problems already mentioned of varied scales and of lack of clear identifying information come in again. On the one hand we have churches like the episcopal church of Freising, which is clearly an agent, in the same way that a monastery is: a known and locatable corporate entity which persists and takes actions. On the other, there are the (presumably) small, rural churches whose very location is unknown. In 776, for example, Charlemagne confirmed an exchange of a church between Abbot Alan of Farfa and Bishop Theoto of Rieti: the charter refers simply to "ecclesia sancti Viti" (the church of St Vitus). In a few cases, we know neither the location of the church nor its dedication. Such "anonymous" churches are conceptually possessions rather than agents.
Our rule of thumb, therefore, was to create churches as agents if they seemed to be "acting" in some way (e.g. as the recipient of gifts) and to leave churches as possessions if they were solely the object of transactions. We may need to revisit at some point whether this was the right decision to make or whether the annoyance of creating a small number of very vague agents (unknown and unlocated churches) outweighs the disadvantage of storing data for them in two different kinds of structure.
To add further to the conceptual mess, churches can also be treated as places in charters: e.g. a charter may say that it is "actum in corte Sancti Salbatori" (enacted in the cloister of St Saviour). Here, we decided that our data structures could only be stretched so far: such charters are recorded as being enacted at the (named or unnamed) settlement in which the church is located, with the church recorded as an agent, so that its appearance in the charter can at least be indicated.
BLURRING THE FACTOID MODEL
Such issues concerning the lack of firm boundaries between different types of entity means that our data cannot easily be represented in a straightforward conceptual model; it would end by looking more like this:

The problem is not so much a lack of data analysis on the part of the project team as data that resists such analysis because of its unstructured and vague nature. Future posts in this series will discuss in more detail how we represent agents, places and possessions in the database and how we connect them together via factoids. But this overview already reveals one key point. How we might think of categories such as people, possessions or churches are not necessarily how the producers of Carolingian charters thought of them. This awareness of substantial differences between how early medieval scribes chose to represent the structures and events of their world and how we might want to analyse these is what makes database design for such a project such an intellectually challenging procedure.
REFERENCES
(1) Bradley, John, and Short, Harold, 'Texts into databases: the evolving field of new-style prosopography', Literary and Linguistic Computing 20, Supplement (2005), 3-24 at 8.
(2) Adapted from Bradley, John, and Pasin, Michele, 'Structuring that which cannot be structured: a role for formal models in representing aspects of Medieval Scotland', in Matthew Hammond (ed.), New perspectives on medieval Scotland, 1093-1286, Woodbridge: The Boydell Press, 2013, pp. 203-214 at p. 208
Share: