Posted: Sept. 22, 2014, 8:01 a.m. by Rachel Stone
In my first post in this series I outlined the factoid model we were using to record information, which can be schematically represented as follows:
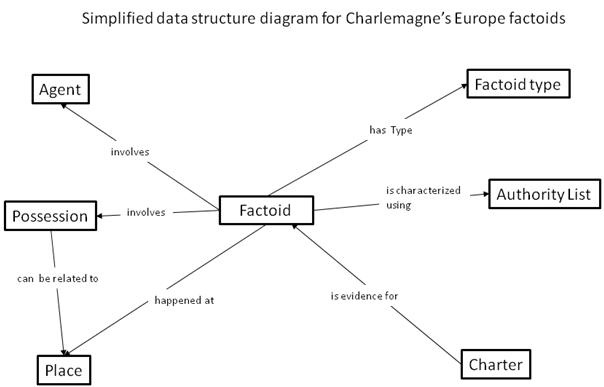
The vast majority of the information we include in the database consists of such factoids: charter-specific assertions about agents (individuals and institutions), places and objects. However, the database has to start with basic data for such entities, which can then be linked together in factoids. This post will discuss how we decided to record identifying information for each agent and the data structures we used.
Agent model: individuals
The key problems when dealing with individuals in a database are firstly their identification and secondly the standardisation of name forms. Both are particularly difficult for the Charlemagne project because of the type of source material we have. Identification is difficult, because, as I’ve discussed before, most of the individuals we’re dealing with are too insignificant to appear in the standard authority databases. For example, For example, VIAF (Virtual International Authority File) contains a record (in fact several) for Fulrad, abbot of St-Denis, but not one for Rado, one of the most active of Charlemagne’s scribes, let alone Rebellis, who turns up in one of Charlemagne’s late charters. In addition, we have names from a particularly wide range of ethnic backgrounds, which makes standardisation harder than for e.g. names in the Prosopography of Anglo-Saxon England (PASE) database.
There is, however, one database we have used extensively: Nomen et Gens. This is our main external authority both for identification of individuals and for standardised spellings of early medieval names, since it provides detailed onomastic data for the eighth century. There are still difficulties in how we makes best use of NeG’s standard names, however, especially since their standardisation often involves the use of phonetic spellings, such as Hrōþaberhtaz for Robert/Rupert etc.
What is more, even the Nomen et Gens database has records for less than half the individuals who appear in our charters (although its coverage of name forms is higher). Our standard practice, therefore, is to create a new agent for each name in a new charter unless we have a strong reason to believe that the agent already exists (either because of specific details of their family or office) or because of a definite identification by the editor of the charter which we accept as plausible. This cautious approach may mean that we have wrongly split agents at time, but this was thought better than wrongly amalgamating two separate individuals. The input interface also includes the option to input possible/probable identifications of two agents with one another, thus allowing for future “tidying” of entries if more information becomes available. We hope for feedback from users if they spot people who can safely be amalgamated.
The basic record for an agent who is an individual person looks like this:
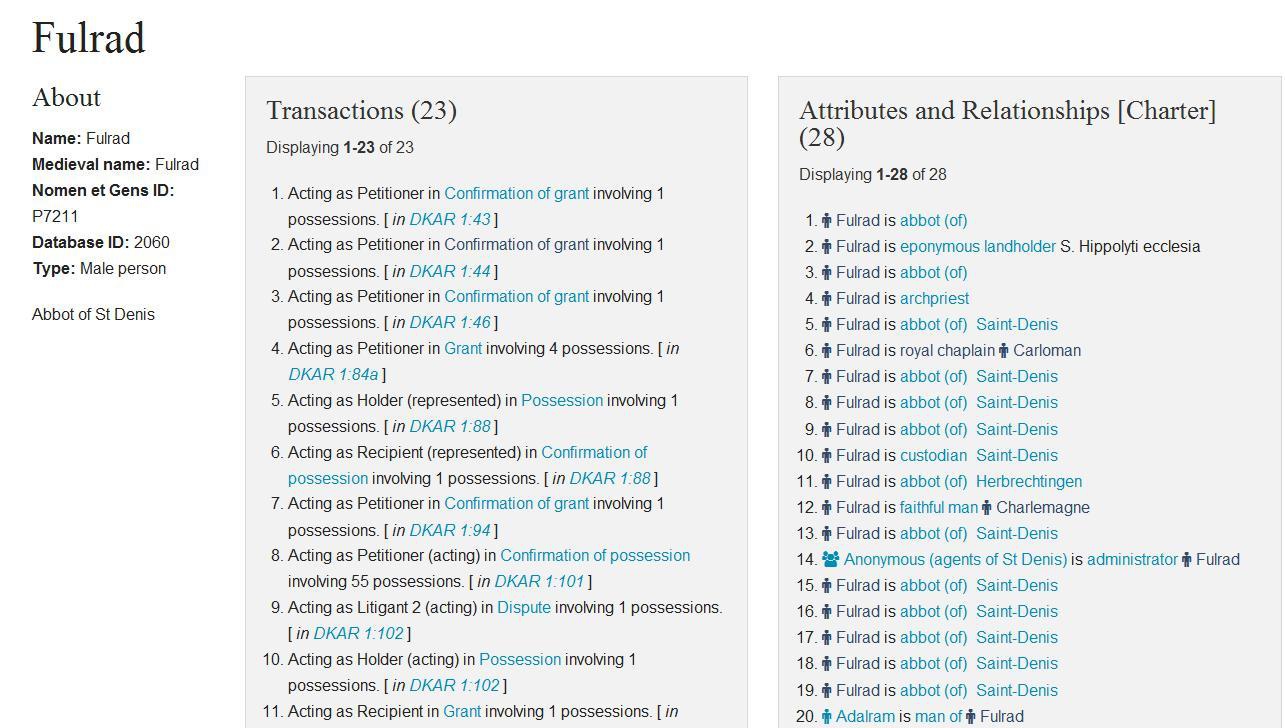
The amount of non-charter-specific information recorded is fairly minimal: standardised modern and medieval names of the person, a brief description of them and the agent type, as well as a field for Nomen et Gens ID. Separate fields for modern and medieval names are mainly a way of ensuring that a few particularly common names and well-known people can be picked up via Anglicised forms. For example, you can search for Charlemagne, even though he is Karolus in many of the charters and for John rather than Iohannes. In the majority of cases, the modern and medieval names are the same, since most early medieval names do not have a “modern” version. We have generally not kept “Latin” endings for “German” names, e.g. we record “Hartrad” for both modern and medieval name, rather than “Hartradus”.
We will probably need to do further work standardising names when we have them all entered. As well as such standardised names, however, we also include charter-specific names: we record the original spellings (including Latin case-endings) for all personal names in a particular charter (with the exception of saints). Thus it will be possible for a user to search for even a severely garbled name from a late copy (such as Gislebertus from DKAR 1:128) and find the proposed identification (in this case Giltbert).
The standardised name fields themselves are basic; they do not include specific structures for entering alternative names or name components. Thus numbers after a name for rulers (e.g. Tassilo III) and alternative names (e.g. Audulf /Fradello* for “Audulfo quem Fradello vocitatur”) are all included in one field. This reflects the naming practices of the societies we cover, in which overwhelmingly one name is used, with no regular use of patronymics, matronymics, proto-surnames etc. While it would have been possible to create such structures, this would have made inputting data more complex in order to provide options that were very rarely used.
This is one of the reasons, incidentally, that cross-searching of name fields across databases is so difficult: naming practices differ so much across time and between regions that databases invariably are optimised to reflect the specific cultures that they deal with. It will be interesting to see how much cross-linking SNAP:DRGN can provide, but its concentration on the ancient world means that it may well produce schema not entirely suited to the specific characteristics of early medieval names.
As well as names, the type of agent is included: this allows the separation out of individuals, groups and particular forms of institution, such as monasteries and churches. It also allows recording the sex of people and institutions, with options to record these as “unknown sex” or “mixed”. This was a key point for me when we were discussing the design of the database, since I have a particular interest in women’s history. Yet even now, some medieval source databases (such as the hagiographical databases BHLms) have been known to omit gender as an analytical category.
This is a particular problem because conventional editions (and also digitised full-text sources) are very inefficient tools for finding women: although it’s normally possibly to distinguish women if you scrutinise a text sufficiently closely, there’s no easy collection of search terms to use to pull out all entries concerning women. Because we have to analyse in detail every charter we include in the database, it makes sense to record the sex of all the agents we find in it.
To do this, we’re using a mix of name information and attributes (bishop, mother etc) to identify people’s sex: we currently have about 300 people out of over 6000 whose sex we can’t identify, which is a reasonably low rate. We’re not, however, making too many assumptions about what roles people of either sex might play: we already have 5 witnesses whom we can identify as female, which I know will be of interest to some researchers. And again, all this data is updatable. If someone lets us know the sex of some of the obscurer names (or points out where we’ve got things wrong), we can update the system. We can also add extra categories if it turns out, for example, that we come across eunuchs and want to record them separately (as Prosopography of the Byzantine World does).
Anonymous people
As David Pelteret explained in 2007 (1), the PASE database decided to include unnamed people in order to exploit fully the information contained in the limited source material (as well as reflecting a more general research concern for the “unnamed” masses at the end of the twentieth century). Among a number of reasons for including such data, David pointed out that individuals not named in one Anglo-Saxon source, but identified in another way (e.g. as someone’s mother) might subsequently appear with a name in another text. In addition, the holders of some occupations and offices (such as messengers) are rarely named: in order to assess the significance of named messengers, it was useful to be able to compare the characteristics of the anonymous ones in the sources.
The same reasons apply with even greater force for the source material of the Charlemagne database, since our focus was not solely on individuals, but also on socio-economic data. Two types of people are particularly likely to be recorded in early medieval charters without names: women and the unfree. For example, so far 14 out of 57 of the mothers in the database are anonymous (25%) as opposed to 26 out of 137 of the fathers (20%). Meanwhile, 117 out of 693 (17%) of those recorded as unfree do not have their names recorded, whereas they form less than 10% of the overall agents in the database. If we are to give as full a picture as possible of Carolingian society, we need to include anonymous agents whenever doing so provides extra information, either about the attributes of people or about the transaction in which they appear.
As well as anonymous individuals, we also have anonymous groups included within the database. The basic record for such a group looks like this:
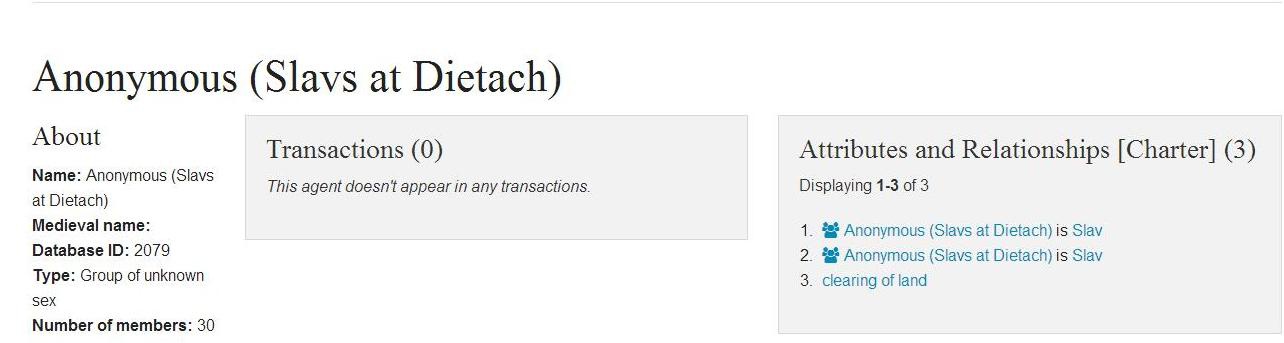
We have included a field for the number of agents (for the relatively few cases where we are told this) and instead of a name, they are given a brief description. Most anonymous agents appear only in a single charter, so identification is not an issue. However, we do include a few “generic” groups, where the membership of a group is likely to change over time, but we have no details on its composition at any particular moment. Thus, for example, whenever Charlemagne, as a condition of a charter, wants prayers said for “his children”, with no identified names, a single agent is used to record this, allowing us to see the pattern of such usage. In contrast, there is one charter from Prüm in which there are prayers for the anonymous children of Charlemagne and Hildegard: this group is regarded as a separate agent.
Institutional agents
Institutional agents, such as monasteries and churches are also recorded in the same agent model. Standardisation of names is again a problem here and we therefore do not include medieval names for institutions, since they are so varied. For modern names, we tend to be guided by Wikipedia for institutions that still exist, since there is no other obvious source that covers all types of ecclesiastical institutions across Europe. Otherwise, we use a standard form: Location, S <name of dedication>, with wider geographical terms used if we cannot specify an exact location, e.g. “Chur, S John” and “France, S Leodgar”. There still remain some small churches about which we have very little information, but the expectation is that these will not appear in many charters and so that duplication of agents can be avoided.
We also record in the agent model all the known dedications of institutional agents and their location. Here, there is a compromise between speed of data inputting and precision. Both dedications and locations of institutional agents can (in theory) change between charters: a particular institution can be referred to by a different set of saints, and it can be relocated (see e.g. the wandering monks of St Philibert).
Some databases dealing with religious institutions (such as the Who were the nuns? project) therefore include fields within their database structure which allow inputting a location of the relevant convent in each individual record. However, we chose not to do so, because of the characteristics of our dataset. The vast majority of early medieval charters which survive include a monastery or an episcopal church, so that we would need to create hundreds of repetitive factoids to state, for example, that in a particular charter the monastery of Fulda was still in Fulda and still dedicated to St Boniface. The additional useful information created, did not, to our minds, outweigh the extra work involved in doing this (and might swamp the user with information of marginal usefulness). Instead, locations and dedications are recorded as static attributes of monasteries and churches. Again, however, full text names in records for specific charters will pick up many of the variants.
Conclusion
Our handling of agents indicates the practical limits both of databases and of input protocols: despite the authoritative appearance of such data once it is online, there are always problems with data quality and consistency. The decisions that we make on such matters do not come purely from a theoretical framework, but emerge from practice and engagement with the underlying documents. As this series will show, the creation of database structures for such problematic data is as much an art as a science. It reflects what we think will help the user; as David Pelteret points out (2), our decisions even on basic aspects of the database coverage also inevitably reflect our own priorities and values.
References
(1) Pelteret, David, ‘Should one include unnamed persons in a prosopographical study?’ In Prosopography approaches and applications: a handbook, edited by K. S. B. Keats-Rohan, (Oxford, Unit for Prosopographical Research, Linacre College, University of Oxford, 2007), pp. 183-196
(2) Ibid., pp. 195-196
Share:
